# 搜索
在 Typesense 中,搜索包含对一个或多个文本字段的查询(query)以及对数值或分面(facet)字段的过滤条件列表。您还可以对结果进行排序和分面处理。
示例响应
:::提示
Typesense 默认会对结果进行分页,每页默认显示 10 条匹配结果。
您可以使用 page 和 per_page 参数来控制分页,或者使用基于偏移量的分页方式,即 offset 和 limit 参数。更多关于分页的内容,请参阅分页参数文档部分。
:::
当查询一个 string[] 类型的字段时,highlights 结构会包含对应片段匹配的数组索引。例如:
# 搜索参数
# 查询参数
| 参数名 | 是否必填 | 描述 |
|---|---|---|
| q | 是 | 要在集合中搜索的查询文本。 使用 q: "*"(通配符操作符)作为搜索字符串可以返回所有文档。这通常与 filter_by 结合使用时特别有用。例如,要返回所有匹配过滤条件的文档,可以使用: q=*&filter_by=num_employees:10。用双引号包围词语可以进行精确短语搜索。例如:将 q 设置为 "tennis ball"(包括双引号)将只返回那些按此精确顺序包含这两个词的文档,且不进行拼写容错。要在查询中明确排除某些词,可以在词前加上 - 操作符,例如 q: 'electric car -tesla'。 |
| query_by | 是 | 一个或多个应该被查询的字段名。多个字段用逗号分隔:company_name, country字段的顺序很重要:匹配列表中靠前字段的记录被认为比匹配靠后字段的记录更相关。因此,在上面的例子中,匹配 company_name 字段的文档会排在匹配 country 字段的文档之前。只有集合模式中数据类型为 string 或 string[] 的字段才能在 query_by 中指定。此外,object 和 object[] 字段也支持通过搜索其子级的 string 和 string[] 字段进行查询。关于嵌套对象字段的更多信息,可以阅读这里。 |
| prefix | 否 | 表示查询中的最后一个词应被视为前缀,而不是完整词。这对于构建自动补全和即时搜索界面是必要的。设置为 false 可以禁用所有查询字段的前缀搜索。你也可以按字段控制前缀搜索的行为。例如,如果你正在查询3个字段,并且只想在第一个字段上启用前缀搜索,可以使用 ?prefix=true,false,false。顺序应与 query_by 中的字段顺序匹配。如果为 prefix 指定了单个值,则该值将用于 query_by 中指定的所有字段。默认值: true(所有字段的前缀搜索都启用)。 |
| infix | 否 | 中缀搜索可用于查找包含出现在单词中间的文本片段的文档。例如,我们可以使用中缀搜索来定位单词 AK1243XYZ6789 中的字符串 XYZ。注意: 中缀搜索适用于搜索小字段,如电子邮件地址、电话号码、标识符等,这些场景中缀搜索特别有用。因此,中缀搜索仅使用查询中的 第一个词 进行搜索。 由于中缀搜索需要额外的数据结构,你必须按字段启用它,如下所示: {"name": "part_number", "type": "string", "infix": true }如果为该字段启用了中缀索引,可以通过向搜索查询发送一个逗号分隔的字符串参数 infix 来按字段进行中缀搜索。此参数可以有3个值:
?query_by=title,part_number 查询两个字段,可以通过发送 ?infix=off,always(与 query_by 中的字段顺序相同)仅为 part_number 字段启用中缀搜索。还有两个参数可以控制中缀搜索的范围: max_extra_prefix 和 max_extra_suffix,它们指定在匹配的标记中可以出现在查询之前或之后的额外符号的最大数量。例如:查询 "K2100" 在 "6PK2100" 中有2个额外的前缀符号。默认情况下,匹配可以包含任意数量的前缀/后缀。 |
| pre_segmented_query | 否 | 如果你希望自己将搜索查询分割成空格分隔的词,将此参数设置为 true。当设置为 true 时,我们只会按空格分割搜索查询,而不是使用本地化感知的内置分词器。默认值: false |
| preset | 否 | 用于此搜索的预设名称。 预设允许你保存一组搜索参数,并在搜索时通过一个 preset 参数使用它们。更多关于预设的信息请参阅这里。 |
| vector_query | 否 | 执行最近邻向量查询。更多关于向量搜索的信息。 |
| voice_query | 否 | 转录base64编码的语音录音,并使用转录后的查询进行搜索。更多关于语音查询的信息。 |
| stopwords | 否 | 搜索时要从搜索查询中删除的逗号分隔的单词列表。对于特定集合的每次搜索都持久化的停用词,可以参考停用词文档。 |
| validate_field_names | 否 | 控制Typesense是否应验证字段是否存在于模式中。当设置为false时,如果字段缺失,Typesense不会抛出错误。这对于程序化分组(并非所有字段都可能存在)非常有用。 默认值: true |
# 拼写容错参数
| 参数名 | 是否必填 | 描述 |
|---|---|---|
| num_typos | 否 | 允许的最大拼写错误数量(0、1 或 2)。 使用Damerau–Levenshtein距离 (opens new window)计算错误数量。 可以按字段控制 num_typos。例如,查询3个字段时若要在第一个字段禁用拼写容错,使用?num_typos=0,1,1。顺序需与query_by中的字段顺序一致。若为num_typos指定单一值,则该值将应用于query_by中所有字段。默认值: 2(query_by中所有字段的num_typos均为2)。 |
| min_len_1typo | 否 | 应用1个拼写错误纠正的最小词长。num_typos的值仍被视为最大允许错误数。默认值: 4。 |
| min_len_2typo | 否 | 应用2个拼写错误纠正的最小词长。num_typos的值仍被视为最大允许错误数。默认值: 7。 |
| split_join_tokens | 否 | 将空格视为拼写错误:若未找到q=basketball则搜索q=basket ball,反之亦然。仅当原始查询无结果时才会尝试分词/合并。设为always则始终触发此行为,设为off则禁用。要在其他特殊字符上分词,可在创建集合时使用此表中的 token_separators设置。默认值: fallback。 |
| typo_tokens_threshold | 否 | 若设为数字N,当搜索词的结果数不足N时,Typesense将开始查找拼写纠正变体,直到找到至少N个结果(最多纠正num_typo次)。设为0可禁用拼写容错。默认值: 1 |
| drop_tokens_threshold | 否 | 若设为数字N且查询含多个词(如wordA wordB),当同时包含wordA和wordB的文档不足N个时,Typesense将丢弃wordB并仅搜索含wordA的文档。Typesense会如此从左到右和/或从右到左持续丢弃关键词,直到找到至少N个文档。结果数最少的词会优先被丢弃。设为0可禁用词丢弃功能。默认值: 1 |
| drop_tokens_mode | 否 | 控制当查询中的原始词未出现在任何文档中时,丢弃词的顺序方向。 可选值: right_to_left(默认)、left_to_right、both_sides:3关于 both_sides:3的说明:对于不超过3个词(token)的查询,此模式会从两侧丢弃词并穷举所有匹配结果。若查询长度超过3个词,Typesense将回退至默认的right_to_left行为。 |
| enable_typos_for_numerical_tokens | 否 | 设为false可禁用数字查询词的拼写纠正。默认值:true。 |
| enable_typos_for_alpha_numerical_tokens | 否 | 设为false可禁用字母数字查询词的拼写纠正。默认值:true。 |
| synonym_num_typos | 否 | 允许对查询中拼写纠正后的词进行同义词解析。 默认值: 0 |
# 过滤参数
| 参数名称 | 是否必填 | 描述 |
|---|---|---|
| filter_by | 否 | 用于优化搜索结果的过滤条件。 一个字段可以匹配一个或多个值。 示例: - country: USA- country: [USA, UK] 返回 country 为 USA 或 UK 的文档。精确与非精确过滤: 要完全匹配字符串字段的值,可以使用 :=(精确匹配)操作符。例如:category := Shoe 将匹配 category 设置为 Shoe 的文档,而不会匹配 category 设置为 Shoe Rack 的文档。使用 :(非精确)操作符将在字段上进行词级别的部分匹配,不考虑词的位置(因此通常更快)。例如:category:Shoe 将匹配 category 为 Shoe、Shoe Rack 或 Outdoor Shoe 的记录。提示:如果某个字段在所有文档中的值都不包含空格,并且你想对其进行过滤,建议使用 : 操作符以提高性能,因为它会避免进行词位置检查。转义特殊字符: 你也可以使用多个值进行过滤,并使用反引号表示字符串字面量: category:= [`Running Shoes, Men`, `Sneaker (Men)`, Boots]。否定: 不等于/否定通过 :!= 操作符支持,例如 author:!=JK Rowling 或 id:!=[id1, id2]。你也可以否定多个值:author:!=[JK Rowling, Gilbert Patten]要排除在过滤时_包含_特定字符串的结果,可以这样做: artist:! Jackson 将排除所有 artist 字段值包含单词 jackson 的文档。数值过滤: 使用范围操作符 [min..max] 或简单比较操作符 >、>=、<、<=、= 来过滤具有数值在最小和最大值之间的文档。你可以在数值字段模式上启用 "range_index": true 以实现快速范围查询(不过这会增加索引的内存使用)。示例: - num_employees:<40- num_employees:[10..100]- num_employees:[<10, >100]- num_employees:[10..100, 140](过滤值在10到100之间或正好为140的文档)。- num_employees:!= [10, 100, 140](过滤值不是10、100或140的文档)。多条件: 你可以使用 && 操作符分隔多个条件。示例: - num_employees:>100 && country: [USA, UK]- categories:=Shoes && categories:=Outdoor要在_不同_字段上进行OR操作(例如:颜色是蓝色或类别是鞋子),可以使用 || 操作符。示例: - color: blue || category: shoe- (color: blue || category: shoe) && in_stock: true数组过滤: filter_by 也可以用于数组字段。 例如:如果 genres 是一个 string[] 字段:- genres:=[Rock, Pop] 将返回 genres 数组字段包含 Rock 或 Pop 的文档。- genres:=Rock && genres:=Acoustic 将返回 genres 数组字段同时包含 Rock 和 Acoustic 的文档。前缀过滤: 你可以像这样过滤以特定前缀字符串开头的记录: company_name: Acm*这将返回 company_name 字段中任何单词以 acm 开头的文档,例如 Corporation of Acme。你可以将字段级匹配操作符 := 与前缀过滤结合使用,如下所示:name := S*这将返回 name: Steve Jobs 的文档,但不会返回 name: Adam Stator 的文档。地理过滤: 更多关于地理搜索和过滤的信息,请参阅专门章节。 在API密钥中嵌入过滤器: 你可以将 filter_by 参数(或其部分)嵌入到范围搜索API密钥中,以设置文档的条件访问控制和/或强制执行使用该API密钥的任何搜索请求的过滤器。更多关于范围搜索API密钥的信息,请参阅专门章节。 |
| enable_lazy_filter | 否 | 以增量/惰性方式应用过滤操作。当可能过滤大值但查询中的token预计匹配很少文档时,将此设置为 true。默认值:false。 |
| max_filter_by_candidates | 否 | 控制Typesense在 filter_by 值上进行模糊搜索时考虑的相似词数量。对于控制像 company_name:Acm* 这样的前缀匹配很有用。默认值:4。 |
| validate_field_names | 否 | 控制Typesense是否应验证过滤字段是否存在于模式中。当设置为false时,如果过滤字段缺失,Typesense不会抛出错误。这对于编程式过滤非常有用,因为并非所有字段都可能存在。 默认值: true |
# 排序与相关性参数
| 参数名称 | 是否必填 | 描述 |
|---|---|---|
| query_by_weights | 否 | 为每个 query_by 字段指定相对权重,用于结果排序。取值范围为 0 到 127。可用于在匹配时优先提升某些字段的优先级。权重值用逗号分隔,顺序与 query_by 字段一致。例如:query_by_weights: 1,1,2 配合 query_by: field_a,field_b,field_c 会给 field_a 和 field_b 相同权重,而 field_c 的权重是前两者的两倍。默认值:若未显式指定权重, query_by 列表中靠前的字段将获得更高权重。 |
| text_match_type | 否 | 在多字段匹配场景下,此参数决定如何计算记录的文本匹配得分。 可选值: max_score(默认)、max_weight 或 sum_score。默认的 max_score 模式会取所有字段中最高的文本匹配得分作为记录的代表性得分。当两条记录的文本匹配得分相同时,字段权重将作为决胜依据。max_weight 模式会使用权重最高字段的文本匹配得分作为记录的代表性相关性得分。sum_score 模式会汇总各字段的文本匹配得分,得出整体文档级别的得分。更多信息请参阅文本匹配得分类型。 |
| sort_by | 否 | 用于结果排序的字段列表及其排序方向。多个字段用逗号分隔。 单次搜索查询最多可指定3个排序字段,它们将作为决胜条件——如果第一条 sort_by 字段的值相同,则使用第二条字段的值来决胜,若仍相同则使用第三条字段。若所有3个字段都相同,则按文档插入顺序决胜。例如: num_employees:desc,year_started:asc这将按 num_employees 降序排序,若两条记录的 num_employees 相同,则用 year_started 字段决胜。文本相似度得分可通过特殊字段 _text_match 在排序字段列表中使用。若指定了1或2个排序字段, _text_match 将作为最后一个决胜字段使用。默认值: 若未指定 sort_by 参数,结果将按 _text_match:desc,default_sorting_field:desc 排序。字符串值排序:详见此处。 空值排序:详见此处。 条件排序(即可选过滤):详见此处。 地理排序:使用地理搜索时,可通过 location_field_name(48.853, 2.344):asc 围绕给定经纬度排序文档。还可以在半径范围内按其他字段排序。详见此处。 |
| prioritize_exact_match | 否 | 默认情况下,Typesense 会优先显示字段值与查询完全匹配的文档。设为 false 可禁用此行为。默认值: true |
| prioritize_token_position | 否 | 让 Typesense 优先显示查询词在文本中出现位置更靠前的文档。 默认值: false |
| prioritize_num_matching_fields | 否 | 让 Typesense 优先显示查询词在更多字段中出现的文档。 默认值: true |
| pinned_hits | 否 | 无条件固定在搜索结果特定位置的记录列表。 典型用例是在搜索结果顶部展示或推广特定项目。 格式为逗号分隔的 record_id:hit_position。例如:要将ID为123的记录固定在位置1,ID为456的记录固定在位置5,应指定 123:1,456:5。也可使用 Overrides 功能基于规则覆盖搜索结果。执行顺序为:先应用 Overrides,然后是 pinned_hits,最后是 hidden_hits。 |
| hidden_hits | 否 | 无条件从搜索结果中隐藏的记录列表。 格式为逗号分隔的 record_ids。例如:要隐藏ID为123和456的记录,应指定 123,456。也可使用 Overrides 功能基于规则覆盖搜索结果。执行顺序为:先应用 Overrides,然后是 pinned_hits,最后是 hidden_hits。 |
| filter_curated_hits | 否 | 搜索查询的 filter_by 条件是否应用于人工干预结果(覆盖定义、固定结果、隐藏结果等)。默认值: false |
| enable_overrides | 否 | 若已定义某些覆盖规则但想在特定搜索查询中禁用所有规则,可将 enable_overrides 设为 false。默认值: true |
| override_tags | 否 | 可通过此参数触发带有特定标签的覆盖规则。详见此处。 |
| enable_synonyms | 否 | 若已定义某些同义词但想在特定搜索查询中禁用所有同义词,可将 enable_synonyms 设为 false。默认值: true |
| synonym_prefix | 否 | 允许在查询词前缀上解析同义词。 默认值: false |
| max_candidates | 否 | 控制 Typesense 为前缀搜索和错字搜索考虑的相似词数量。 默认值: 4(若启用 exhaustive_search 则为 10000)。例如:搜索 "ap" 会匹配数据集中以 "ap" 开头的 "apple"、"apply"、"apart"、"apron" 等数百个相似词。搜索 "jofn" 会匹配数据集中与 "john"、"joan" 等1个错字以内的所有变体。 但出于性能考虑,Typesense 默认只考虑前 4 个前缀和错字变体。可通过 max_candidates 搜索参数配置这个 4 的值。简言之,若搜索短词如 "a" 时未返回所有预期记录,应增加 max_candidates 值和/或在集合模式中修改 default_sorting_field 以使用记录中的某种流行度分数定义"优选"结果。 |
# 分页参数
| 参数 | 是否必填 | 描述 |
|---|---|---|
| page | 否 | 指定要获取的页码结果。 页码从 1 开始表示第一页。默认值: 1 |
| per_page | 否 | 每次获取的结果数量。 当使用 group_by 时,per_page 表示每页获取的 分组 数量,以正确保持分页。默认值: 10 注意: 每页最多只能获取 250 条结果(或使用 group_by 时的分组结果)。 |
| offset | 否 | 指定从结果集中返回结果的起始位置。可作为 page 参数的替代方案。 |
| limit | 否 | 每次获取的结果数量。可作为 per_page 参数的替代方案。默认值: 10。 |
# 分面参数
| 参数 | 是否必填 | 描述 |
|---|---|---|
| facet_by | 否 | 用于结果分面的字段列表。多个字段用逗号分隔。 可以通过关联 sort_by 参数对分面值进行字母排序显示,例如 phone(sort_by: _alpha:asc)。也可以基于兄弟字段的值进行分面排序,如:recipe.name(sort_by: recipe.calories:asc)。要对数值范围进行分面,可以指定范围标签,例如 "facet_by": "rating(Average:[0, 3], Good:[3, 4], Great:[4, 5])"(了解更多) |
| facet_strategy | 否 | Typesense 支持两种高效分面策略,并内置启发式规则自动选择合适策略。有效值为 exhaustive、top_values 和 automatic(默认)。exhaustive:此策略会遍历所有匹配文档的 facet_by 字段,统计每个唯一分面值的文档数量。当文档数量较少(少于数万)和/或请求的分面值数量(由 max_facet_values 定义)较大时效果最佳。top_values:此策略通过反向索引(存储 {分面字段值=>[包含该值的所有文档列表]} 的映射)查找每个分面字段值,然后计算匹配文档列表与分面值文档列表的交集长度来获取分面计数。当匹配结果很多时效率较高,因为只需对顶部高频分面值进行交集运算。但如果需要获取的分面值数量(由 max_facet_values 配置)很大且匹配结果很少,此策略效率会低于 exhaustive 策略。另一个缺点是 total_values 的统计不精确,因为只考虑了有限数量的分面值进行交集计算。automatic:Typesense 会根据上述启发式规则自动选择最佳策略,此为默认值。 |
| max_facet_values | 否 | 返回的分面值的最大数量。 默认值: 10 |
| facet_query | 否 | 可通过此参数过滤返回的分面值,匹配的分面文本会高亮显示。例如当按 category 分面时,设置 facet_query=category:shoe 将只返回包含前缀 "shoe" 的分面值。对于分面查询,如果未指定 per_page 参数,默认会设为 0,此时仅返回分面结果而不返回匹配文档。如需同时获取匹配文档,请确保将 per_page 设为非零值。使用 facet_query_num_typos 参数可控制此分面值过滤的模糊容错度。 |
| facet_query_num_typos | 否 | 控制分面查询过滤的模糊容错度。默认值:2。 |
| facet_return_parent | 否 | 传入以逗号分隔的嵌套分面字段字符串,这些字段的父对象将在分面响应中返回。例如设置为 "color.name" 时,会在分面响应中以 parent 属性返回父对象 color。 |
| facet_sample_percent | 否 | 用于估算分面计数的匹配文档百分比。 分面抽样有助于提高大数据集的分面计算速度,适用于UI界面不需要精确计数的场景。 默认值: 100(默认禁用抽样)。 |
| facet_sample_threshold | 否 | 启用分面抽样的最小匹配文档数阈值。 分面抽样有助于提高大数据集的分面计算速度,适用于UI界面不需要精确计数的场景。 默认值: 0。 |
| validate_field_names | 否 | 控制Typesense是否验证分面字段是否存在于schema中。设为false时,即使分面字段缺失也不会报错。适用于编程式分面场景,某些分面字段可能不存在的情况。 默认值: true。 |
# 分组参数
| 参数名 | 是否必填 | 描述 |
|---|---|---|
| group_by | 否 | 通过指定一个或多个 group_by 字段,可以将搜索结果聚合到组或桶中。多个字段用逗号分隔。注意:要对特定字段进行分组,该字段必须是分面(faceted)字段。 例如: group_by=country,company_name |
| group_limit | 否 | 每组返回的最大命中数。如果 group_limit 设置为 K,则每组只返回前 K 个命中结果。默认值: 3 |
| group_missing_values | 否 | 将此参数设置为 true 时,所有在 group_by 字段中值为 null 的文档将被归入一个单独组。设置为 false 时,每个在 group_by 字段中值为 null 的文档将不会被分组。默认值: true |
| validate_field_names | 否 | 控制Typesense是否验证分组字段是否存在于schema中。设置为false时,即使分组字段不存在,Typesense也不会报错。这对于某些字段可能不存在的程序化分组场景很有用。 默认值: true |
# 结果参数
| 参数名称 | 是否必填 | 描述 |
|---|---|---|
| include_fields | 否 | 文档中需要包含在搜索结果中的字段列表,用逗号分隔。 |
| exclude_fields | 否 | 文档中需要从搜索结果中排除的字段列表,用逗号分隔。 您可以在范围限定的 API 密钥中使用此参数,从搜索 API 响应中排除/隐藏潜在敏感字段如 out_of 和 search_time_ms。提示:如果您的文档包含向量字段,通常建议将该字段名添加到 exclude_fields 以节省网络带宽并避免浪费 CPU 周期。 |
| highlight_fields | 否 | 需要进行片段高亮的字段列表,用逗号分隔。片段是包含最多匹配标记的文本部分,这些标记也会作为 matched_tokens 出现在响应中。您也可以使用此参数高亮未查询的字段。 默认值:所有查询字段都会被高亮。 设置为 none 可完全禁用片段高亮。 |
| highlight_full_fields | 否 | 需要完整高亮(不进行片段截取)的字段列表,用逗号分隔。 默认值:所有字段都会进行片段截取。 设置为 none 可完全禁用高亮。 |
| highlight_affix_num_tokens | 否 | 高亮文本两侧应包含的标记数量。这控制片段的长度。 默认值: 4 |
| highlight_start_tag | 否 | 用于高亮片段的开始标签。 默认值: <mark> |
| highlight_end_tag | 否 | 用于高亮片段的结束标签。 默认值: </mark> |
| enable_highlight_v1 | 否 | 用于禁用响应中已弃用的旧高亮结构的标志。 默认值: true |
| snippet_threshold | 否 | 字段值长度低于此阈值时将完整高亮,而不是显示相关部分的片段。 默认值: 30 |
| limit_hits | 否 | 可以从集合中获取的最大命中数。例如:200page * per_page 应小于此数字,搜索请求才能返回结果。默认值:无限制 通常您会希望生成一个嵌入了此参数的范围限定的 API 密钥,并使用该 API 密钥执行搜索,这样它会自动应用且无法在搜索时更改。 |
| search_cutoff_ms | 否 | 如果截止时间已过,Typesense 将尝试提前返回结果。这不是严格保证,分面计算不受此参数限制。 默认值:不进行搜索截止。 |
| exhaustive_search | 否 | 设置为 true 将使 Typesense 详尽考虑查询中所有前缀变体和拼写纠正,而不会在找到足够结果时提前停止(忽略 drop_tokens_threshold 和 typo_tokens_threshold 配置)。默认值: false |
# 缓存参数
| 参数 | 是否必填 | 描述 |
|---|---|---|
| use_cache | 否 | 启用服务端搜索结果的缓存。默认情况下缓存是禁用的。 当使用 multi_search 时,此参数需要作为 URL 查询参数指定,而不是在 POST 请求体中。 默认值: false |
| cache_ttl | 否 | 确定搜索查询缓存时长的秒数。此值只能作为限定范围的API密钥的一部分设置。 默认值: 60 |
# 过滤结果
你可以使用 filter_by 搜索参数来根据特定值或逻辑表达式过滤结果。
例如:如果你有一个电影数据集,可以应用过滤器只返回特定类型的电影或在某个日期之后发布的电影等。
🔗 你可以在上方的过滤参数表格中找到关于 filter_by 的详细文档。
# 分面结果
您可以使用 facet_by 搜索参数让 Typesense 返回一个或多个字段值的聚合计数。
对于整数字段,Typesense 除了计数外,还会返回最小值、最大值、总和和平均值。
🔗 您可以在上方的分面参数表中找到关于 facet_by 的详细文档。
示例:如果您有一个类似下方截图的歌曲数据集 (opens new window),左侧"发行日期"和"艺术家"旁边的**计数**就是通过对 release_date 和 artist 字段进行分面统计获得的。
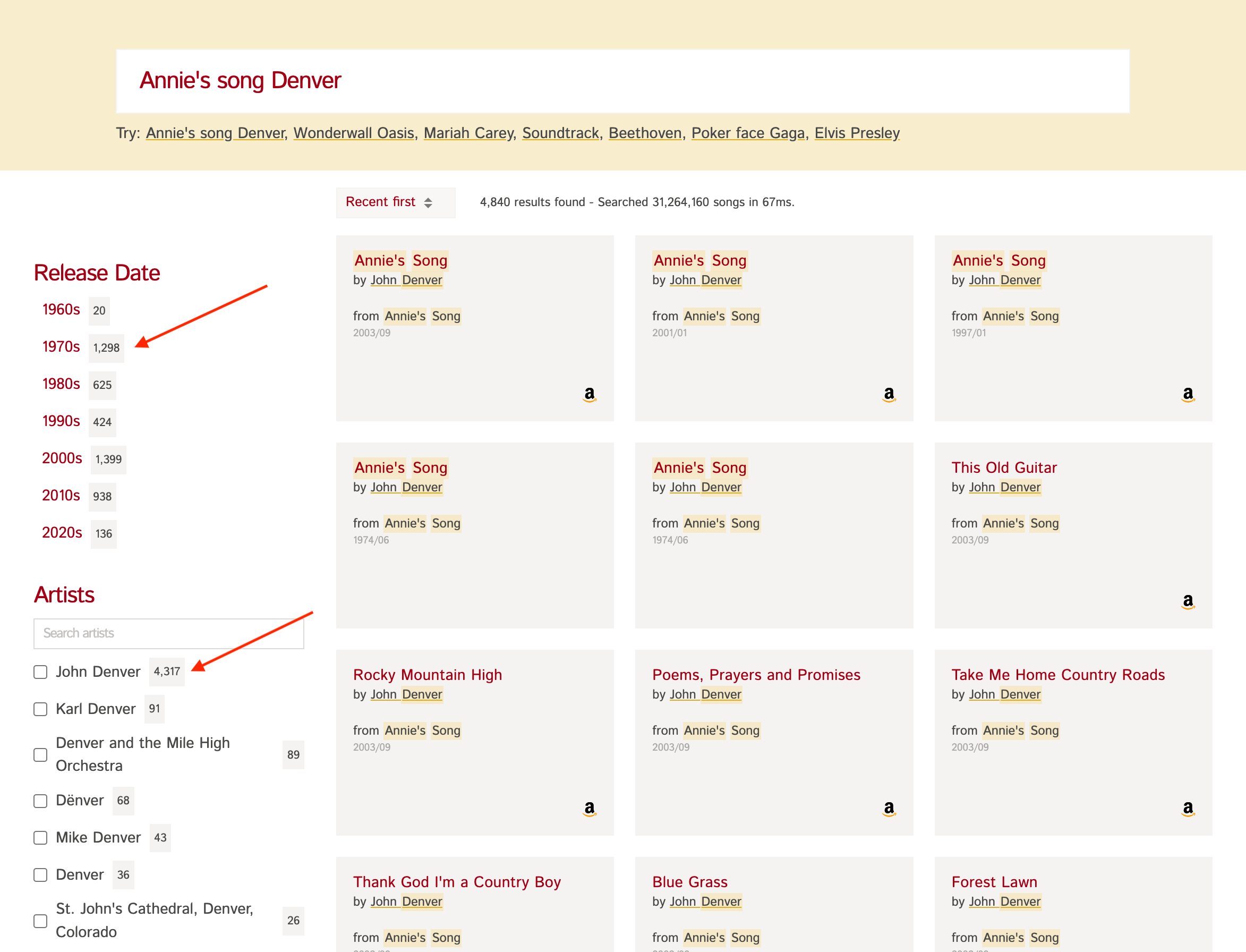
这对于向用户展示结果摘要非常有用,他们可以进一步优化结果以高效找到所需内容。
请注意,在 facet_by 中使用字段前,您需要先在集合模式中为该字段启用分面功能,如下所示:
{
fields: [
{
facet: true,
name: "<field>",
type: "<datatype>"
}
]
}
# 分面值排序
可以通过关联 sort_by 参数按字母顺序对分面值进行排序显示,例如 phone(sort_by: _alpha:asc)。
您还可以根据兄弟字段的值对分面进行排序,例如:recipe.name(sort_by: recipe.calories:asc)
# 映射分面字符串
将嵌套分面字段的逗号分隔字符串传递给 facet_return_parent 参数,该参数的父对象将在分面响应中返回。
例如,当您将其设置为 facet_return_parent: color.name 时,这将在分面响应中返回父 color 对象作为 parent 属性。
# 分面范围(Facet ranges)
对于数值型字段,您可以提供一系列范围及其对应的标签,用于对文档进行分面统计。
例如,如果您的文档包含一个 rating 评分字段,并且您希望将评分分为 average(一般)、good(良好)和 great(优秀)三个等级,可以这样配置:
{
"facet_by": "rating(Average:[0, 3], Good:[3, 4], Great:[4, 5])"
}
这会将 rating 值分配到指定的范围区间,并统计每个区间内的文档数量来生成分面计数。
注意:范围起始值包含在内,而范围结束值本质上是不包含的(左闭右开区间)。
您可以留空起始值或结束值来分别表示最小值和最大值。在下面的示例中,others 分面标签的最大值被省略,表示将包含所有大于等于 100 的值:
{
"facet_by": "price(economy:[0, 100], others:[100, ])"
}
按范围分面要求字段必须启用 sort 属性。默认情况下所有数值型字段都已启用该属性,除非您明确配置为禁用。
🔗 您可以在上方的分面参数表格中找到关于 facet_by 的详细文档。
# 结果排序
您可以使用 sort_by 搜索参数来对结果进行排序,最多支持 3 个字段的级联排序机制:
- 如果第一个字段的值相同,则使用第二个字段排序
- 如果前两个字段的值都相同,则使用第三个字段来决断
文本相似度得分通过特殊的 _text_match 字段暴露,您可以将其包含在排序字段列表中。
🔗 您可以在上方的排序参数表格中找到关于 sort_by 的详细文档。
# 数值排序
默认情况下,所有数值型和布尔型字段都已启用排序功能。您可以直接在 sort_by 参数中使用这些字段。
# 字符串字段排序
只有当集合模式中某个字符串字段启用了 sort 属性时,才允许对该字段进行排序。
例如,以下是一个集合模式,其中允许对 email 字符串字段进行排序:
{
"name": "users",
"fields": [
{"name": "name", "type": "string" },
{
"name": "email",
"type": "string",
"sort": true
}
]
}
在上面定义的 users 集合中,可以对 email 字段进行排序,但 name 字段不可排序。
TIP
对字符串字段排序需要构建单独的索引,对于长字符串字段(如 description)或大型数据集可能会消耗大量内存。因此,应当谨慎地只为相关字符串字段启用排序功能。
# 基于条件的排序
您可以使用特殊的 _eval(<表达式>) 操作作为 sort_by 参数,根据任何评估结果为 true 或 false 的表达式来排序文档。
_eval() 内部的表达式语法与 filter_by 搜索参数相同,因此我们也将此功能称为"可选过滤"。
例如:
{
"sort_by": "_eval(in_stock:true):desc,popularity:desc"
}
这将使 in_stock 设置为 true 的文档排在前面,然后是 in_stock 设置为 false 的文档。
您可以使用逻辑运算符组合表达式,就像在 filter_by 搜索参数中一样:
{
"sort_by": "_eval(has_relevant_experience:true && location:(48.853,2.344,5.1 km)):desc,application_date:desc"
}
这将优先考虑具有相关工作经历且位于总部5公里半径范围内的候选人。
# 基于过滤评分的排序
除了像上面那样仅按 true / false 值排序外,我们还可以为匹配一系列过滤条件的记录提供自定义评分。
例如,如果我们有一个 shoes 集合,并且希望将所有 Nike 鞋排在 Adidas 鞋之前,可以这样做:
{
"sort_by": "_eval([ (brand:Nike):3, (brand:Adidas):2 ]):desc"
}
_eval 中可以包含任意数量的表达式,每个表达式都可以像标准的 filter_by 表达式一样复杂。
# 对空值或缺失值的排序处理
对于可选的数值字段,缺失值或 null 值总是会被排在最后,无论排序顺序如何。
对于可选的字符串字段,空值("")、缺失值或 null 值被视为具有"最高"值,因此在升序排序时,这些值会被放在结果末尾。同理,在降序排序时,这些值会被放在结果顶部。
对于数值和字符串字段,您都可以使用 missing_values 参数来改变这一行为。例如,以下是如何确保在升序排序时将标题为 null/空/缺失的值放在结果集顶部:
sort_by=title(missing_values: first):asc
同理,要确保在降序排序时将 null/空/缺失值放在结果末尾:
sort_by=title(missing_values: last):desc
missing_values 的可选值为:first 或 last。
# 随机排序
您可以使用 sort_by 中的特殊参数 _rand() 来实现搜索结果的随机排序。可以选择性地提供一个种子值,该值必须为正整数。
例如,使用特定种子:
{
"sort_by": "_rand(42)"
}
或者不使用种子值(此时将使用当前时间戳作为种子):
{
"sort_by": "_rand()"
}
使用特定种子值会在多次搜索中产生相同的随机排序结果,这在需要保持随机一致性时非常有用(例如用于 A/B 测试或结果抽样)。而不带种子值的 _rand() 会在每次请求时产生不同的随机排序。
您可以将随机排序与其他排序字段结合使用:
{
"sort_by": "_rand():desc,popularity:desc"
}
TIP
- 当未提供种子时,将使用当前时间戳作为种子
- 当提供种子时,必须为正整数
- 使用相同种子将产生相同的随机排序
- 不同的种子值(或不使用种子)将产生不同的随机排序
# 基于枢轴值排序
您可以使用 sort_by 中的 pivot 参数来根据特定枢轴值对结果进行排序。这在需要基于与参考点的距离来排序项目时特别有用。
例如,如果您有时间戳数据并希望基于与特定时间戳的接近程度进行排序:
{
"sort_by": "timestamp(pivot: 1728386250):asc"
}
这将按以下方式排序结果:
- 使用
asc:最接近枢轴值的值排在最前面,随后是较远的值 - 使用
desc:离枢轴值最远的值排在最前面,随后是较近的值
以枢轴值1728386250按升序排序时的示例结果:
timestamp: 1728386250 (与枢轴值完全匹配)
timestamp: 1728387250 (距离枢轴值1000)
timestamp: 1728385250 (距离枢轴值1000)
timestamp: 1728384250 (距离枢轴值2000)
timestamp: 1728383250 (距离枢轴值3000)
您可以将枢轴排序与其他排序字段结合使用:
{
"sort_by": "timestamp(pivot: 1728386250):asc,popularity:desc"
}
此功能适用于:
- 基于与参考日期/时间的接近程度排序
- 围绕目标数值组织数值
- 创建"更接近"类型的排序体验
# 衰减函数排序
衰减函数允许您根据结果与目标值的距离进行评分和排序,分数会按照不同的数学函数递减。这在以下场景特别有用:
- 在基于时间的排序中提升近期项目
- 实现基于距离的相关性
- 在数值范围内创建平滑的衰减效果
您可以在 sort_by 参数中使用衰减函数,语法如下:
{
"sort_by": "field_name(origin: value, func: function_name, scale: value, decay: rate):direction"
}
# 参数
| 参数名 | 是否必填 | 描述 |
|---|---|---|
origin | 是 | 计算衰减函数的参考点。必须为整数。 |
func | 是 | 使用的衰减函数。支持的值: gauss, linear, exp, 或 diff |
scale | 是 | 从原点开始的距离,在此距离处分数应按衰减率衰减。必须为非零整数。 |
offset | 否 | 应用于原点的偏移量。必须为整数。默认为 0。 |
decay | 否 | 分数衰减的速率,介于 0.0 和 1.0 之间。默认为 0.5。 |
# 示例
假设您有一个包含时间戳的产品集合,并希望按照与特定日期接近程度进行排序:
curl -H "X-TYPESENSE-API-KEY: ${TYPESENSE_API_KEY}" \
"http://localhost:8108/collections/products/documents/search\
?q=smartphone\
&query_by=product_name\
&sort_by=timestamp(origin: 1728385250, func: gauss, scale: 1000, decay: 0.5):desc"
对于包含以下记录的数据集:
{"product_name": "Samsung Smartphone", "timestamp": 1728383250}
{"product_name": "Vivo Smartphone", "timestamp": 1728384250}
{"product_name": "Oneplus Smartphone", "timestamp": 1728385250}
{"product_name": "Pixel Smartphone", "timestamp": 1728386250}
{"product_name": "Moto Smartphone", "timestamp": 1728387250}
结果将根据每个时间戳与原点(1728385250)的接近程度排序,分数按照高斯函数递减:
- Oneplus Smartphone (与原点完全匹配 - 最高分)
- Pixel Smartphone (距离原点1000单位 - 衰减分数)
- Vivo Smartphone (距离原点1000单位 - 衰减分数)
- Moto Smartphone (距离原点2000单位 - 进一步衰减分数)
- Samsung Smartphone (距离原点2000单位 - 进一步衰减分数)
# 支持的函数
gauss: 高斯衰减 - 平滑的钟形曲线下降linear: 线性衰减 - 恒定速率下降exp: 指数衰减 - 分数快速下降diff: 基于差值的衰减 - 与原点简单的线性差值
TIP
decay参数决定分数下降的速度 - 值越小衰减越快- 使用
gauss实现平滑下降,linear实现恒定下降,exp实现快速下降 scale决定分数以指定速率衰减的距离阈值
# 文本匹配分数分桶
当按文本匹配分数(_text_match)排序时,Typesense 提供两种不同的分桶方法:buckets 和 bucket_size。这两个参数都允许您在应用次要排序条件前,将具有相似相关性分数的结果分组。
# 使用 buckets 参数
buckets 参数将结果划分为指定数量的等大小组:
{
"sort_by": "_text_match(buckets: 10):desc,weighted_score:desc"
}
这种方法:
- 获取所有匹配结果
- 将它们划分为指定数量的等大小桶(例如10个桶)
- 强制每个桶内的所有结果具有相同的文本匹配分数
- 在每个桶内应用次要排序条件(例如
weighted_score)
例如,如果您有100个结果并指定buckets: 10,每个桶将包含10个被视为具有同等相关性的结果,然后按次要标准排序。
# 使用 bucket_size 参数
另一种方式是使用bucket_size参数将结果分组为固定大小的桶:
{
"sort_by": "_text_match(bucket_size: 3):desc,points:desc"
}
例如,如果您针对以下记录搜索"mark":
[
{"title": "Mark Antony", "points": 100},
{"title": "Marks Spencer", "points": 200},
{"title": "Mark Twain", "points": 100},
{"title": "Mark Payne", "points": 300},
{"title": "Marks Henry", "points": 200},
{"title": "Mark Aurelius", "points": 200}
]
使用bucket_size: 3时,Typesense会:
- 根据文本匹配分数将结果分组为每3条记录的桶
- 在每个桶内按points降序排序
这确保了具有相似文本匹配相关性的记录保持在一起,同时在其相关性组内按points排序。
bucket_size参数接受:
- 任何正整数:将结果分组为指定大小的桶
0:禁用分桶(默认行为)
# 在 buckets 和 bucket_size 之间选择
- 当您希望确保特定数量的相关分组时(无论结果总数多少),请使用
buckets - 当您希望保持一致的桶大小时(无论结果总数多少),请使用
bucket_size - 较少数量的
buckets或较大的bucket_size意味着更强调次要排序字段 - 当
bucket_size大于结果数量时,不会进行分桶操作
# 分组结果
您可以通过指定一个或多个 group_by 字段将搜索结果聚合成组或桶。
这种分组方式在以下场景非常有用:
- 去重:通过使用一个或多个
group_by字段,您可以合并搜索结果中的项目并移除重复项。例如,如果有多个相同尺码的鞋子,通过设置group_by=size&group_limit=1,您可以确保搜索结果中每种尺码只返回一只鞋子。 - 纠正偏差:当搜索结果被特定类型的文档主导时,您可以使用
group_by和group_limit来纠正这种偏差。例如,如果某个查询的搜索结果中包含过多相同品牌的文档,您可以设置group_by=brand&group_limit=3来确保每个品牌只返回前 3 个结果。
:::提示 要对特定字段进行分组,该字段必须是分面(faceted)字段。 :::
分组返回的命中结果采用嵌套结构,这与我们之前看到的普通 JSON 响应格式不同。让我们用 group_by 参数重复之前的查询:
定义
GET ${TYPESENSE_HOST}/collections/:collection/documents/search
# 按分组大小排序
您还可以通过在 sort_by 子句中使用 _group_found 来按分组的大小对结果进行排序。
{
"sort_by": "_group_found:desc"
}
您可以在上方的分组参数表格中找到这些分组参数的详细文档。
# 分页
您可以使用 page 和 per_page 搜索参数来控制结果的分页。也可以使用基于偏移量的分页参数 offset 和 limit。
默认情况下,Typesense 会返回前 10 条结果(page: 1, per_page: 10)。
您可以在上方的分页参数表格中找到这些分页参数的详细文档。
# 排序机制
默认情况下,Typesense 会根据计算出的 text_match 相关性分数对结果进行排序。
您可以使用各种搜索参数来影响文本匹配分数,按附加参数排序结果,以及有条件地提升或隐藏结果。 更多信息请参阅排序与相关性指南。
# 预设配置
搜索预设功能允许您将一组搜索参数存储在一起,并通过名称引用它们。这样在进行搜索请求时,只需使用预设名称,而不必在每次搜索请求中单独传递所有搜索参数。
您可以在Typesense端修改预设配置来调整搜索参数,无需重新部署应用程序。
例如,您可以创建一个名为listing_view的预设配置,执行通配符搜索并按popularity分数排序结果。
让我们创建一个名为listing_view的预设:
在搜索操作中,您可以使用preset搜索参数引用这个预设配置。
以下示例展示的是multi_search端点,但您也可以在单个搜索端点中使用preset参数。
TIP
预设配置中的value键也可以匹配联邦/多搜索的搜索参数。例如:
await client.presets().upsert("listing_view", {
value: {
searches: [
{
collection: "products",
q: "*",
sort_by: "popularity",
},
{
collection: "blog_posts",
q: "*",
sort_by: "published_at:desc",
}
],
},
})
通常建议使用单搜索预设以获得灵活性。然后您可以在多搜索请求中使用preset参数组合它们。
TIP
显式传递给搜索端点的查询参数将覆盖预设值中存储的参数。