# 常见问题解答
以下是我们过去收到的一些常见问题及其解答。
# 目录
# 关键词搜索
# 什么是前缀搜索?
如果你的数据集中有像 example 这样的单词,当你搜索 exa(前3个字符)时,在前缀搜索模式(prefix=true 搜索参数)下仍然会返回单词 example。
以下是在前缀搜索中会匹配到 example 的所有其他搜索词:
eexexaexamexampexamplexample
这在构建"边输入边搜索"体验时非常有用,当用户逐个字符输入时,你希望即使输入部分词也能立即显示结果。
你可以把前缀搜索理解为"以...开头"的搜索 - 搜索词必须出现在字符串的开头才会被视为匹配。
Typesense 默认启用前缀搜索。
但如果禁用前缀搜索(通过设置 prefix=false 作为搜索参数),则只有完整输入 example 作为搜索关键词时才会返回结果,而上述所有 example 的子字符串都不会返回结果。
# 什么是中缀搜索(infix search)?
如果你的数据集中有一个像 example 这样的单词,而你搜索 xa(出现在字符串中间),默认情况下 Typesense 不会返回它,因为默认只启用了前缀搜索。
如果你想在字符串中间进行搜索,这被称为 infix(中缀)搜索,需要为每个字段显式启用。
在集合模式(collection schema)的字段定义中,添加 infix: true 参数(文档见此处),然后在搜索时使用 infix 搜索参数(文档见此处)。
WARNING
中缀搜索会消耗大量 CPU 资源,并且需要额外的内存。对于高流量场景,请确保在启用此功能前对集群进行基准测试,确认具备足够的 CPU 容量。
如果单词中包含特殊字符,一个更高效的替代方案是在集合模式中使用 token_separators,让 Typesense 将单词索引为单独的 token,这样你就可以在每个 token 上进行搜索,而无需使用中缀搜索。
# 如何处理特殊字符?
默认情况下,Typesense 在索引前会移除所有特殊字符。
你可以使用 token_separators 和 symbols_to_index 参数来控制这一行为。
这里有一篇详细文章,通过示例说明如何在不同类型数据搜索中使用这两个参数。
# 如何处理关键词的单复数变体?
在 Typesense 中有两种方式处理单词变体(如单复数形式):
# 1. 使用基础词干提取
您可以使用内置的词干提取功能自动处理数据集中的常见词形变化(例如:单复数、时态变化等)。
例如:当启用词干提取时,搜索 walking 也会返回包含 walk、walked、walks 等变体的结果。
您可以通过在集合模式(collection schema)的字段定义中设置 stem: true 参数来启用词干提取。
# 2. 使用自定义词干词典
注意
自定义词干词典仅在 v28.0 及以上版本可用。
为了更精确地控制词形变化,您可以使用自定义词干词典来定义单词与其词根形式之间的精确映射关系。
首先,通过上传包含单词映射的 JSONL 文件创建词典:
{"word": "meetings", "root":"meeting"}
{"word": "people", "root":"person"}
{"word": "children", "root":"child"}
使用词干词典 API 上传该词典:
curl -X POST \
-H "X-TYPESENSE-API-KEY: ${TYPESENSE_API_KEY}" \
--data-binary @plurals.jsonl \
"http://localhost:8108/stemming/dictionary/import?id=my_dictionary"
然后在集合模式中通过设置 stem_dictionary 参数启用该词典:
{
"name": "companies",
"fields": [
{"name": "title", "type": "string", "stem_dictionary": "my_dictionary"}
]
}
关于词干提取的更多细节,请阅读 词干提取文档。
# 当我搜索短字符串时,为什么没有返回所有结果?如何解决?
默认情况下,出于性能考虑,Typesense 只会考虑前 4 个前缀匹配项。
举个例子:
搜索 "ap" 会匹配数据集中所有以 "ap" 开头的记录,如 "apple"、"apply"、"apart"、"apron" 等数百个类似词汇。同样,搜索 "jofn" 会匹配数据集中所有与 "john"、"joan" 等 1 个拼写错误范围内的变体。
但出于性能考虑,Typesense 默认只考虑前 4 个前缀和拼写变体。这个 4 可以通过 max_candidates 搜索参数进行配置,相关文档见此处。
简而言之,如果你搜索像 "a" 这样的短词时没有返回所有预期记录,你可以:
- 将
max_candidates调高 - 修改集合模式中的
default_sorting_field,通过记录中的某种流行度分数来定义"优先级"(否则 Typesense 只会使用每个前缀的记录数量来确定优先级)
# 为什么关键词顺序会影响搜索结果数量?
通常有以下几种原因:
默认情况下,Typesense 仅对搜索查询的最后一个词执行前缀搜索。
例如:
假设您搜索
hello worl,只有worl会用于前缀搜索,而hello需要完全匹配。因此,对于
hello worl这个(前缀)搜索查询,将返回以下所有记录:- ✅
hello world - ✅
hello worlds - ✅
hello worldwide - ✅
hello worldwide - ✅
hello worldy - ✅
hello worldly
但以下记录不会在
hello world搜索查询中返回:- ❌
hellow world - ❌
hellowy world - ❌
hellos world - ❌
hellowing world
这是因为
hello不是前缀搜索的,因为它不是搜索查询中的最后一个词。但如果现在翻转搜索词的顺序,搜索查询变为
world hello,那么上述四条记录将会被返回,因为此时hello成为前缀搜索的词。如果您想禁用前缀搜索,可以设置
prefix=false。- ✅
默认情况下,当多关键词搜索查询没有找到结果时,Typesense 会逐个丢弃查询中的词,并重复搜索直到找到足够的结果。
上述"足够"的定义可以通过
drop_tokens_threshold搜索参数配置,而丢弃方向(从左到右 vs 从右到左)可以通过drop_tokens_mode参数配置。因此,如果搜索查询是
hello world,且没有记录包含所有关键词,Typesense 会丢弃world并重新搜索hello。 现在,如果搜索查询是wordl hello,且没有记录包含所有关键词,Typesense 这次会丢弃hello并重新搜索,这将产生与之前不同的结果。
# 如何搜索多个集合并将结果合并到单个排序列表中?
使用联合搜索(Union Search)
从 v28.0 版本开始,Typesense 提供了 union 功能,允许你将多个集合的搜索结果合并为一个有序的命中集合。这是在多个集合间实现联合搜索(federated search)的推荐方法。
curl 'http://localhost:8108/multi_search?page=1&per_page=10' -X POST \
-H "X-TYPESENSE-API-KEY: ${TYPESENSE_API_KEY}" -d '
{
"union": true,
"searches": [
{
"collection": "products",
"q": "wireless headphones",
"query_by": "name,description"
},
{
"collection": "articles",
"q": "wireless headphones",
"query_by": "title,content"
}
]
}'
使用 union 功能时:
- 所有集合的结果会被合并到一个排序列表中
- 分页功能无需客户端处理即可正常工作
- 排序必须使用所有集合中相同类型的字段
替代方案
如果您不想使用 union 功能,或者正在使用较旧版本的 Typesense,您仍然可以通过以下方法实现联合搜索:
在进行联合/多重搜索时,Typesense 为每个命中结果返回的 text_match 分数可用于比较来自不同集合的文档相关性,并在客户端聚合结果。
不过,使用这种客户端聚合方法时,分页可能会变得复杂。
另一个替代方案是将不同类型的文档存储在 单个 集合中(您需要在模式中将所有集合字段设置为 optional: true),并添加一个 document_type 字段来标识记录类型,这样您就可以在应用程序中访问该文档类型的相应字段。
例如,假设您有两种数据类型 products 和 articles,并希望在一个列表中显示结果。
您可以创建一个包含产品和文章的单一集合,将所有字段设为可选,添加一个名为 document_type: product | article 的字段来标识文档是产品还是文章。
当您发送搜索查询时,现在两种类型的记录都会返回在同一个排序列表中,您可以使用 document_type 字段在搜索界面中直观地区分每种类型的记录。
# 如何确保返回结果中包含搜索查询中的所有关键词?
您需要将 drop_tokens_threshold: 0 设置为搜索参数。
关于此功能如何工作的更多背景信息,请阅读以下部分:q 搜索参数
# 我能在 Typesense 中实现布尔搜索吗?
可以,但有一些注意事项需要额外考虑。
让我们先从一些背景知识开始,介绍可用于实现布尔搜索的功能。
# q 搜索参数
Typesense 有一个 搜索参数 叫做 q,它可以接受任何全文搜索词。提供的搜索词会在 query_by 参数指定的所有字段中进行搜索。
默认情况下,如果在数据集中没有找到包含所有搜索词的文档,Typesense 会开始逐个从左到右丢弃 q 参数中的搜索词,并重复搜索操作,直到找到足够多的搜索结果。
上述描述中"足够多"的阈值可以通过 drop_tokens_threshold 搜索参数进行配置,而丢弃关键词的方向则可以通过 drop_tokens_mode 搜索参数进行配置。
例如:假设您执行以下搜索:
{
"q": "senior software engineering manager",
"query_by": "job_title,seniority",
"drop_tokens_threshold": 10,
"drop_tokens_mode": "right_to_left"
}
- Typesense 首先会在
job_title和seniority字段中查找包含全部 4 个搜索词 -senior、software、engineering和manager的同一文档。 - 如果找到的记录少于
10条(通过drop_tokens_threshold配置),Typesense 将继续丢弃搜索词,这次会丢弃manager并重新搜索senior software engineering。 - 如果这个修改后的查询找到至少
10 条记录,Typesense 将停止搜索并返回这些结果。 - 但如果仍然少于
10条记录,Typesense 将丢弃另一个搜索词engineering并重新搜索senior software。 - 如果仍然少于
10条记录,Typesense 将丢弃另一个词并仅搜索senior。
这个过程将持续进行,直到找到至少 10 条结果,或者原始搜索查询中只剩下 1 个搜索词。
# 使用 token-dropping 实现 OR 搜索:
通过上述功能,如果你设置 drop_tokens_threshold: 10000000(实际上可以是任何大于数据集中文档总数的数值),
并设置 drop_tokens_mode: both_sides:3,那么 Typesense 将会依次从搜索查询的两端逐个丢弃关键词,并重复多次搜索,这本质上实现了 OR 操作。
你也可以对特定搜索词使用引号进行分组。例如:senior "software engineering" manager 将确保 software engineering 在记录中以相同顺序存在才能被视为匹配,而其他搜索词则被视为可选项。
# 禁用 token-dropping 实现 AND 搜索:
通过上述功能,如果你设置 drop_tokens_threshold: 0,这将禁用该功能,Typesense 将只返回查询中所有搜索词都在同一记录中存在的记录。
# 使用 filter_by 搜索参数进行布尔搜索:
如果需要执行更结构化的查询,可以使用 filter_by 搜索参数,
它支持带优先级的复杂布尔表达式等。
例如,假设我们想在同一个搜索查询中查找 software engineering lead 或 software engineering manager。
可以这样实现:
{
"q": "*",
"filter_by": "job_title:[software engineering lead, software engineering manager]"
}
如果想查找工作地点为 remote 或 hybrid 的 software engineering lead 记录,可以这样:
{
"q": "*",
"filter_by": "job_title:software engineering lead && job_location:[remote, hybrid]"
}
还可以使用 filter_by 进行"开头匹配"查询。例如,查找所有标题以 software 开头的记录:
{
"q": "*",
"filter_by": "job_title:=software*"
}
# 为什么添加过滤器后有时会返回更多结果?
你可能会遇到这样的情况:在搜索查询中添加过滤器后,返回的结果反而比不加过滤器的相同关键词搜索更多。
这乍看之下似乎违反直觉,因为通常你会预期添加过滤器应该比不加过滤器时_减少_结果数量。
然而,这种行为与 Typesense 处理拼写容错和候选匹配的方式有关,特别是当某个关键词存在多个可能的匹配时。
假设你经营一家服装店,有数千件商品的标题中包含"shoe"这个词。
当你搜索 q: shoe 而不加任何过滤器时,如果该前缀有多个可能的匹配,出于性能考虑,Typesense 默认会将前缀匹配的数量限制为前 4 个前缀。
这个数值 4 可以通过 max_candidates 搜索参数进行配置,相关文档见此处。
但当你添加品牌、颜色、尺码、库存等过滤器后,q: shoe 的搜索空间会缩小,Typesense 就能更高效地进行详尽搜索,返回符合过滤条件的相关结果。
简而言之,当搜索词越通用且匹配项越多(无过滤器时),Typesense 会策略性地裁剪搜索空间,以保持实时搜索的性能。
通常,用户会对通用搜索词添加更多关键词和/或应用更多过滤器,从而获取更精确的结果。
你可以通过增加 max_candidates 参数来控制这一行为,这将使 Typesense 在不加过滤器时考虑更多的前缀匹配。
{
"q": "shoes",
"filter_by": "category:=Athletic",
"max_candidates": 100
}
需要注意的是,增加 max_candidates 会带来性能上的权衡。因此你需要通过实验找到理想值,并关注搜索 API 响应中的 search_time_ms 字段,以找到最适合你用例的设置。
# 语义搜索
# 如何微调语义搜索结果?
语义搜索结果的质量完全取决于您用于生成嵌入向量的机器学习模型,以及最初训练该模型所使用的数据集,还包括维度数量等其他因素。
Typesense 会获取您的搜索查询,使用您指定的 ML 模型为其生成嵌入向量,然后执行最近邻向量搜索,并根据查询向量与每个文档向量之间的余弦相似度对结果进行排序。 与标准关键词搜索不同,在这种搜索模式下,不存在"是否匹配"的二元判断。相反,每个文档都有一个向量距离分数,用于定义它与查询向量的接近程度。
如果您发现语义搜索返回了太多不相关的结果,可以使用 vector_query 中的 distance_threshold 参数来选择一个适合您用例的阈值。了解更多信息请点击这里。
如果您使用混合搜索(Hybrid Search),可以通过 vector_query 的 alpha 参数控制关键词匹配与语义匹配的权重。了解更多信息请点击这里。
您还可以尝试使用不同 ML 模型,选择那些使用与您领域更接近的数据集训练的模型,以生成更好的嵌入向量。
# 分面搜索
# 如何获取用户未筛选条件下的面计数(Facet Counts)?
假设你有一个歌曲搜索界面,需要展示一个可按艺术家筛选的控件:
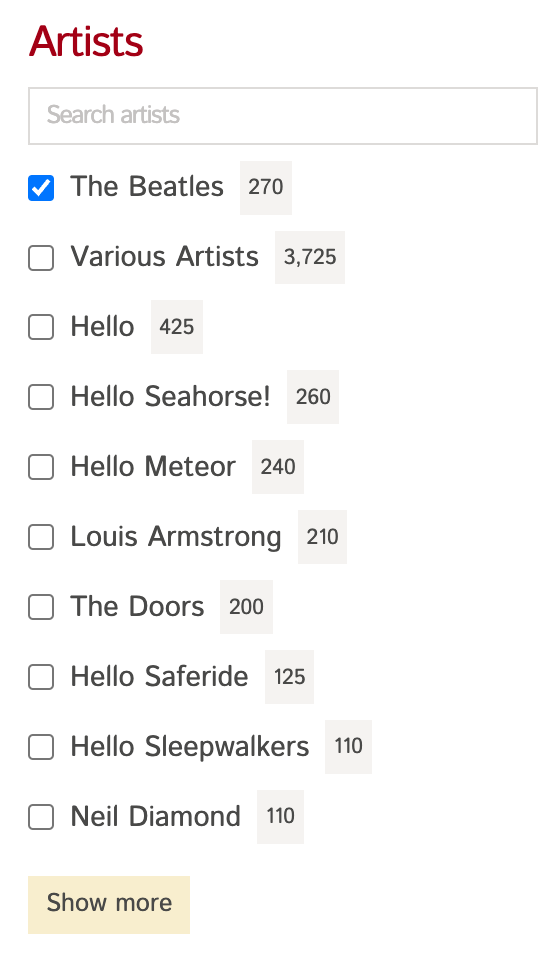
初始使用 facet_by: artist 时,你会获得搜索结果中所有艺术家的面计数。
但当应用 filter_by: artist:=The Beatles 后,再使用 facet_by: artist,结果集将只包含艺术家为"The Beatles"的文档,因此面计数也仅会显示该值。
但你仍需要向用户展示未筛选项的计数。例如上图中,你仍需获取"Various Artists"、"Hello"、"Hello Searhorse!"等选项的计数。
要获取这些计数,你需要执行第二次搜索查询,移除用户选择的 filter_by 条件,仅发送 facet_by: artist 参数。这样就能获取所有未筛选项的面计数,用于筛选控件的显示。
建议通过 multi_search 请求执行第二次查询,这样仍能保持单次HTTP请求。
若有多个筛选控件,需为每个控件额外发送一次查询,移除该控件对应的筛选条件,但保留其他所有筛选条件。
实时示例
查看实际查询结构示例,请访问 songs-search.typesense.org (opens new window),打开浏览器开发者控制台的网络标签页。
在搜索栏输入"Hello",然后点击"The Beatles"。
在开发者控制台网络标签页中查找 multi_search 请求,观察生成的查询结构。
# 过滤(Filtering)和分面(Faceting)有什么区别?
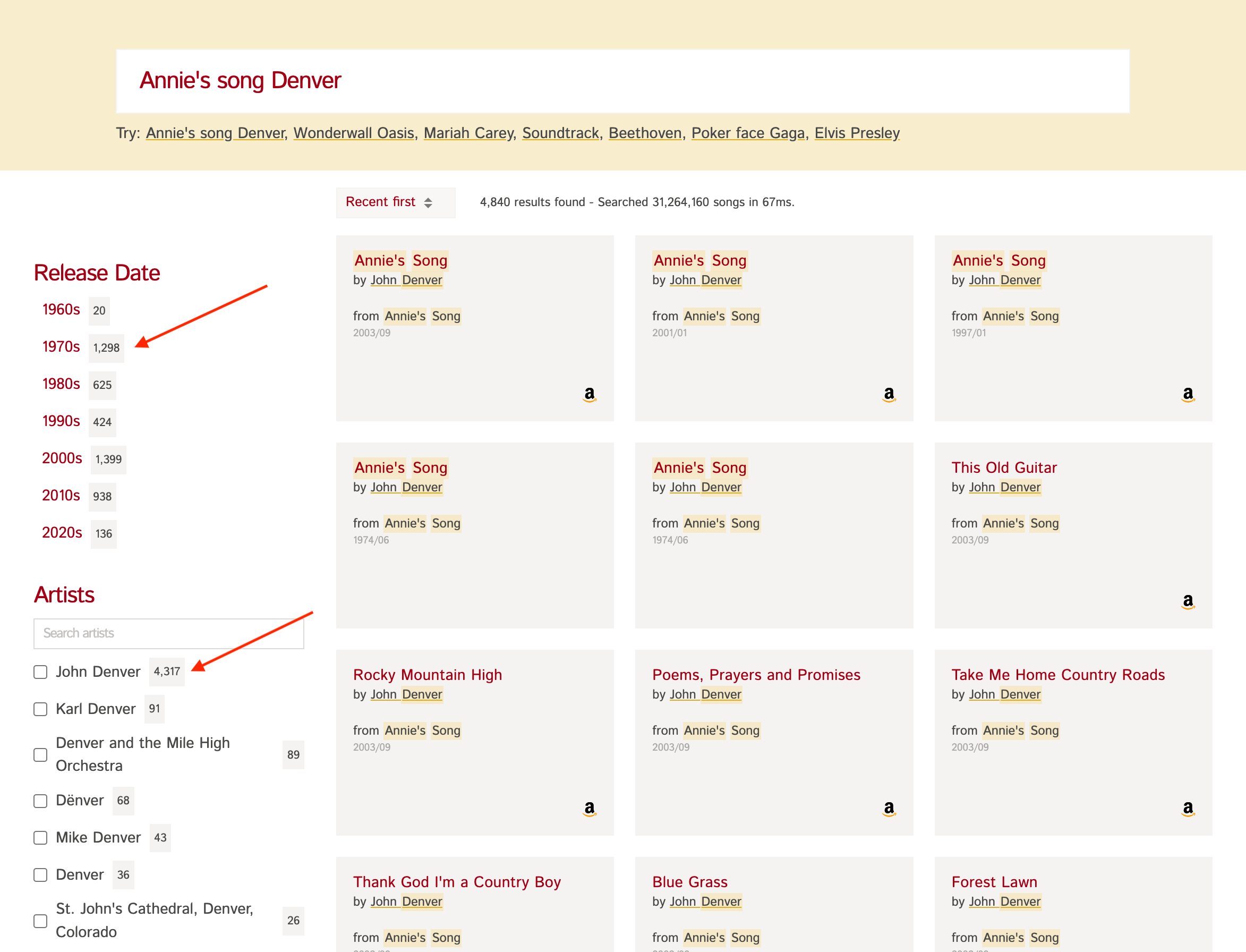
假设你有一个歌曲数据集 (opens new window),如下方截图所示。
左侧"Release Dates"和"Artists"旁边显示的**计数**是通过对release_date和artist字段进行分面统计得到的。
如果你点击例如"John Denver"并只想获取艺术家为"John Denver"的歌曲,这就称为过滤。
# 索引相关
# 为什么从数据库同步的数据没有全部出现在Typesense中?
如果你使用import API端点批量导入文档到Typesense,
该端点在所有情况下都会返回HTTP 200状态码,即使有部分文档导入失败(为了考虑部分成功的情况)。
因此你的HTTP客户端可能不会在出错时抛出异常。
请务必检查API响应中是否存在{success: false, ...}的记录,查看是否有因模式验证错误等原因导致导入失败的文档。
你可以使用?return_id=true查询参数让Typesense返回具体出错的文档ID。
# 运维相关
# 如何获取单个集合或字段的内存使用情况?
Typesense不会跟踪单个集合或字段的内存使用情况,仅会统计整个进程级别的内存指标。
你可以通过GET /metrics.json端点访问这些聚合指标。
# 如何为 Typesense 设置 HTTPS?
默认情况下,Typesense 运行在端口 8108 上并提供 HTTP 服务。
要启用 HTTPS,您需要将 api-port 改为 443,然后使用 ssl-certificate 和 ssl-certificate-key 参数分别指向您的 SSL 证书和 SSL 私钥。
像 LetsEncrypt (opens new window) 这样的供应商提供免费的 SSL 证书。
# 我看到 HTTP 503 错误,"Not Ready or Lagging"。为什么?
如果在写入时看到 HTTP 503,这是由于 Typesense 内置的反压机制导致的。本节讨论如何处理这些 HTTP 503 错误。
如果在重启后看到 HTTP 503,请参阅下文。
# 我重启了 Typesense,现在看到 HTTP 503。为什么?
Typesense 是一个内存数据库。当您重启 Typesense 进程时,我们会读取之前发送到 Typesense 的数据(并作为备份存储在磁盘上),并用它来重新构建内存索引。 这个过程所需的时间取决于您的数据集大小。因此在数据完全重新索引到 RAM 之前,节点将返回 HTTP 503。
为了避免这种停机时间,您应该将 Typesense 设置为高可用性配置,这样即使一个节点需要重启,集群中的其他节点也能继续提供服务而不会停机。
如果在写入时看到 HTTP 503,这是由于 Typesense 内置的反压机制导致的,相关文档请参阅处理写入时的 503 错误部分。
# 我看到大量待处理的写入批次,如何加速处理?
这种情况通常发生在向 Typesense 发送大量单文档写入请求时。建议改用批量导入 API,具体方法请参考高容量写入章节。
# 版本发布
# Typesense 的下个版本何时发布?
我们通常以持续迭代的方式添加功能和修复问题,每 1-2 周发布一次 RC(Release Candidate,候选发布)版本。当变更积累到一定规模后,我们会冻结新版本的功能开发,解决最后一轮问题(如果有的话),运行性能基准测试和回归测试,持续进行内部试用。如果一切顺利,就会发布最终的 GA(Generally Available,正式发布)版本。
由于我们希望最终版本经过充分测试且足够稳定,因此没有固定的 GA 发布时间表。不过在过去,我们大约每 2-3 个月会发布一次 GA 版本 (opens new window)。
在此期间,大多数 RC 版本都可以安全地用于生产环境。更多信息请参阅:可以在生产环境运行 RC 版本吗?
# 如何规划产品路线图?
我们采用即时规划(Just-In-Time)方式,最多提前2个月制定计划。即便在这个时间窗口内,我们也倾向于根据用户反馈重新调整优先级。因此,您在路线图 (opens new window)上看到的超过一个版本周期的项目可能会发生变化。
虽然我们通常会优先考虑优先支持 (opens new window)用户、Typesense Cloud (opens new window)用户、GitHub赞助者 (opens new window)和开源社区贡献者的需求,但我们也基于以下因素确定优先级:
- 需求人数的多少
- 足够小的功能/修复,可以在开发其他相关功能时一并解决
- 有助于提高系统稳定性和相关性的改进
- 能解决让我们兴奋的独特用例
如果您希望某个需求获得优先处理,我们建议您提供详细的使用场景说明,可以通过在现有issue下评论(除了点赞外)或创建新issue来提交。您分享的关于如何使用该功能的详细背景信息将非常有帮助。
# 可以在生产环境运行RC版本吗?
通常是可以的。我们往往会快速修复RC版本中的问题。
如果一个构建版本已发布至少1-2周,且没有更新的构建版本,那么在生产环境运行该RC版本应该是安全的。
您可以在我们的Docker仓库标签页 (opens new window)查看最新RC版本的发布时间戳。
# 如何获取 RC(候选发布)版本?
如果您使用的是 Typesense Cloud,可以通过以下路径找到最新的 RC 版本:集群配置 > 修改 > Typesense 服务器版本。RC 版本会显示在版本选择下拉列表的最底部。
如果您是自托管 Typesense,可以在安装指南中将 Docker 镜像、Linux 二进制文件、DEB 和 RPM 包的 URL 版本号替换为 RC 版本。我们不会为其他平台发布 RC 版本。
# Firebase 扩展
这里是 Firebase 扩展的专属 FAQ:https://github.com/typesense/firestore-typesense-search?tab=readme-ov-file#faqs (opens new window)
# Typesense 云服务
# Typesense Cloud 与自托管版本有何区别?
以下是 Typesense Cloud 和自托管版本(在任何 VPS 或其他云上)的对比:
- API 一致性:我们在 Typesense Cloud 中运行与开源发布相同的二进制文件,因此核心 API 和功能完全相同。
- 管理界面:Typesense 自托管版本是纯 API 产品。而在 Typesense Cloud 中,我们提供了可视化界面,可以通过点击操作来浏览数据、设置同义词、别名、覆盖规则、商品推荐等——非常适合团队中的非技术人员自行管理搜索行为,无需占用工程时间。
- 托管基础设施:在 Typesense Cloud 中,我们为您完全托管基础设施。随着规模扩大,我们可以自动为您扩展集群(当您开启此设置时)。建立高可用集群、调整集群容量和升级Typesense 版本都只需点击操作(或可通过API自动化完成),为您的运维团队节省宝贵时间。
- 全球分布式:在 Typesense Cloud 中,我们提供搜索分发网络功能,类似于 CDN,但我们会将完整数据集_复制_到您选择的每个区域(不同于 CDN 只缓存热门内容),距离搜索者最近的节点会响应搜索请求。这降低了网络延迟,为全球用户加速搜索体验。
- 基于角色的访问控制:在 Typesense Cloud 中,我们为团队成员提供基于角色的访问控制,您无需共享 API 密钥就能让团队成员获得界面不同部分的特定访问权限。
- 迁移成本:由于使用相同的二进制文件,您只需导出导入数据即可在自托管和 Typesense Cloud 之间迁移。
- 成本:您需要将 Typesense Cloud 的定价 (opens new window)与在服务器托管商运行同等配置虚拟机的成本进行比较,还需加上自托管所需的基础设施管理工程时间和更新维护成本。通常我们发现,计入工程时间后,Typesense Cloud 更经济,因为我们可以将工程成本分摊给所有客户,从而降低每位用户的成本。
- 支持服务:我们为 Typesense Cloud 提供优先支持 (opens new window),而自托管版本仅提供尽力支持或通常需要自助服务。
# 帮助
# 在这里或文档中找不到我的问题答案怎么办?
请查阅我们的帮助部分,了解如何获取额外帮助。
← AI 图像搜索